Private AI vs Public LLMs: Why Enterprises Can't Use ChatGPT for Sensitive Data
Using ChatGPT or other public LLMs for enterprise workflows risks data leakage, compliance violations, and hallucinated intelligence across legal, edtech, sales, and customer care. Learn why private AI and RAG systems are the only responsible choice for handling confidential data and critical business decisions.
When your security analyst pastes a threat report into ChatGPT for summarization, that data may be used to improve OpenAI's models-and it has already left your organization's perimeter. Permanently.
In April 2023, Samsung engineers accidentally leaked proprietary source code and internal meeting notes by pasting them into ChatGPT. The company subsequently banned the use of generative AI tools on corporate devices entirely. Samsung wasn't naive-their engineers had good intentions and legitimate use cases. But the architecture of public LLMs makes this kind of data loss structurally inevitable.
Since then, similar incidents have multiplied across industries:
- Legal firms accidentally disclosed client contract details to ChatGPT, creating ethics violations
- Edtech platforms exposed student performance data (triggering FERPA fines)
- Sales teams leaked customer intelligence via ChatGPT prompts
- Support teams shared sensitive customer PII during ticket analysis
For enterprise teams handling sensitive data-whether legal documents, student records, customer information, or proprietary business intelligence-sending this to a public AI model is not just a policy violation-it's a breach waiting to happen.
The stakes vary by industry but remain universally high:
The Fundamental Problem With Public LLMs in Enterprise Security
What "Public LLM" Actually Means for Your Data
When you use ChatGPT, Claude, Gemini, or any other commercial AI API without specific enterprise data agreements, your inputs flow to third-party servers, are logged, and-depending on the service tier-may be used for model training.
For professionals across enterprises handling sensitive data:
Legal & Compliance:
- Client documents containing M&A deal terms, NDA-protected information, negotiation strategies
- Contract portfolios with pricing, terms, and strategic negotiation playbooks
- Regulatory documentation covering compliance frameworks and audit findings
Edtech & Education:
- Student performance data and learning outcomes (protected under FERPA-Family Educational Rights and Privacy Act)
- Personally identifiable information (PII) including names, email addresses, and demographic data linked to learning metrics
- Intervention records and curriculum data showing teaching strategy effectiveness
Sales & Revenue Operations:
- Customer intelligence including firmographic data, buying signals, and competitive positioning
- Deal history with negotiated terms, margin data, and win-loss analysis
- Prospect pipeline with confidential pricing strategies and internal sales playbooks
Customer Support & Success:
- Customer interaction history including past issues, workarounds, and deployment details
- Complaint records with specific customer pain points and satisfaction metrics
- Account metadata linking customers to internal processes and confidential service arrangements
...sending any of this to a public LLM is not a grey area. It's a data breach with quantifiable legal, financial, and compliance consequences.
Once your sensitive data reaches a third-party AI server, you cannot enforce your data retention policies, deletion rights, or access controls on it. GDPR's "right to erasure" does not extend to model weights that have been trained on your data.
The Three Failure Modes of Public LLMs Across Enterprise Workflows
1. Data Exfiltration Risk
Public LLMs are internet-connected services. Your query-including any context you provide-travels:
- Across the public internet (TLS, but still leaving your network)
- Through the provider's load balancers and inference infrastructure
- Into logging systems for abuse detection and quality assurance
- Potentially into model fine-tuning pipelines
Each hop is an attack surface. And unlike your internal systems, you have zero visibility into, or control over, these hops.
2. Hallucination in High-Stakes Contexts
Public LLMs have no access to your internal knowledge base. When asked about your specific business context, they generate answers that sound authoritative but are grounded in general training data, not your actual environment.
For legal professionals: "Does this contract clause comply with India's DPDP Act?"-answered confidently but potentially wrong. For edtech: "Will this intervention work for students with learning disability X?"-guessed from generic materials, not your proven outcome data. For sales: "What margins are typical for this deal type?"-based on public market research, not your actual closed-deal history.
In any context, a hallucinated false answer can cost millions in missed legal exposure, student harm, or pricing mistakes.
3. Compliance and Regulatory Violations Across Industries
The regulatory risk of public LLM use extends well beyond cybersecurity. Each industry has specific compliance requirements that prohibit sharing sensitive data with external services:
| Industry | Regulation | Requirement Violated by Public LLM Use | Potential Fine |
|---|---|---|---|
| Legal & Compliance | GDPR (EU) | Data transfer outside EU without adequate safeguards (Article 46) | Up to €20M or 4% annual turnover |
| Legal & Compliance | India DPDP Act | Processing personal data via foreign entity without consent | Up to ₹500Cr or 2% global revenue |
| Education | FERPA (US) | Student record disclosure to unauthorized parties | Up to $43,280 per record |
| Education | India's DPDP Act | Student learning data transfers without parental consent | ₹500Cr+ fines |
| Healthcare | HIPAA (US) | PHI disclosure to unauthorized third parties | Up to $1.5M per violation category |
| Financial Services | PCI-DSS | Cardholder data sent outside compliant infrastructure | De-listing from card networks |
| All Sectors | SOC 2 / ISO 27001 | Vendor risk not assessed; Cloud Act exposure unmitigated | Audit failure, certification loss |
| All Sectors | NIS2 (EU) / Critical Infrastructure | Supply chain security requirements not met | Penalties up to €10M |
The NIST AI Risk Management Framework (AI RMF) explicitly identifies "data privacy and confidentiality" as a core risk category requiring organizational governance-not ad-hoc tool usage.
Private AI vs Public LLMs: A Head-to-Head Comparison
Architecture Comparison
| Dimension | Public LLM (ChatGPT, Claude) | Private AI (Self-hosted / RAG) |
|---|---|---|
| Data residency | Third-party servers, unknown jurisdiction | Your infrastructure, your jurisdiction |
| Training data risk | Your prompts may improve competitor products | No external model training |
| Knowledge currency | Frozen at training cutoff | Real-time access to your internal data |
| Hallucination risk | High for domain-specific queries | Low-answers grounded in cited sources |
| Compliance | Requires costly enterprise agreements, still risky | Fully compliant-no data leaves perimeter |
| Customizability | Prompt engineering only | Fine-tunable, retrieval-augmented |
| Audit trail | None | Full citation and query logging |
| Cost model | Per-token API pricing (scales badly) | Fixed infrastructure cost |
The Knowledge Gap Problem
Public LLMs have a training cutoff. Whatever threat actor TTPs, CVEs, or geopolitical cyber campaigns emerged after that cutoff-the model doesn't know. For security intelligence, this isn't a limitation; it's a disqualifier.
| Public LLM Knowledge | Private AI + RAG Knowledge |
|---|---|
| General cybersecurity knowledge | General cybersecurity knowledge |
| Publicly documented TTPs | Publicly documented TTPs |
| Training cutoff: months ago | Real-time CVE databases |
| No access to internal data | Your internal threat feeds |
| Generic security advice | Historical incident reports |
| No environment context | Network topology & asset inventory |
| Public regulatory text | Client-specific security policies |
A private RAG (Retrieval-Augmented Generation) system retrieves answers from your own documents, updated in real time, and cites sources so analysts can verify every claim. The difference in intelligence quality is not incremental-it's categorical.
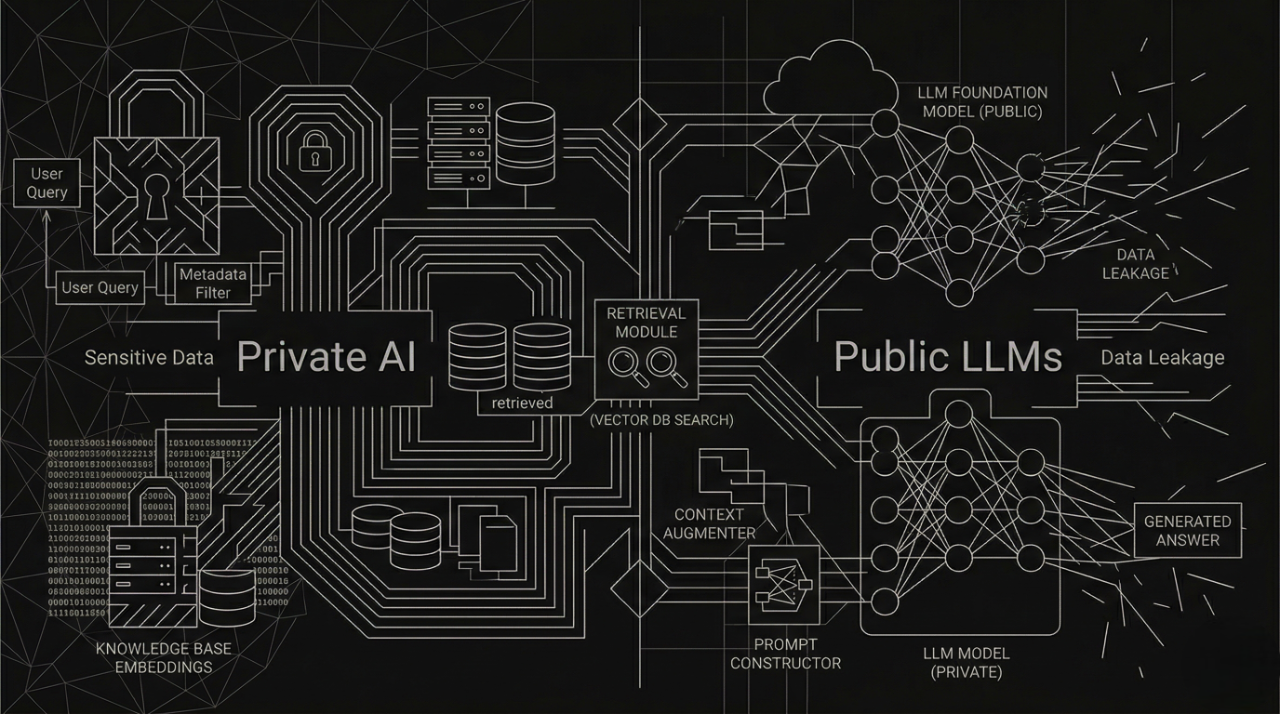
What a Secure Private AI Architecture Looks Like
Building a private AI system for security isn't just about swapping ChatGPT for a self-hosted model. The architecture must be designed for security from the start.
Data Ingestion and Isolation
All internal knowledge sources-threat feeds, IR reports, runbooks, policy documents-are ingested into an isolated vector database. No data leaves the perimeter at any stage.
Data Sources → Chunking → Embedding → Isolated Vector Store
(Threat feeds, IR reports, CVE databases, internal wikis)
Semantic Retrieval Layer
When a security analyst asks a question, the system uses hybrid retrieval (dense semantic search + keyword/BM25 matching) to find the most relevant context from the internal knowledge base-not from the internet.
Evidence-Grounded Generation
A locally-hosted LLM (Llama 3, Mistral, or equivalent) generates answers using only the retrieved context as its source. Every claim is cited back to a specific internal document.
Audit Logging and Access Control
All queries, retrieved contexts, and generated answers are logged with user identity, timestamp, and data classification. Role-based access control ensures analysts see only the data they're authorized for.
Unlike public LLMs that generate confident-sounding speculation, a well-built private RAG system refuses to answer when no relevant internal document exists for a query. This enforced epistemic humility is precisely what security decision-making requires.
Real-World Scenarios Where Public LLMs Fail (and Private AI Succeeds)
Scenario 1: Legal Contract Compliance & Due Diligence Analysis
With Public LLM (ChatGPT): A corporate counsel pastes a vendor contract into ChatGPT asking: "Does this data processing clause comply with GDPR and India's Digital Personal Data Protection Act?" ChatGPT generates plausible-sounding legal analysis-but it's based on publicly available legal summaries, not your organization's contract precedents, negotiated amendment history, or actual compliance policies. The attorney relies on it and unknowingly agrees to non-compliant data transfer provisions. Three months later: regulatory violation and a €50,000+ fine.
With Private AI (Phoebe): Phoebe searches your contract repository, compliance policies, and internal legal precedents simultaneously. It returns: "This clause conflicts with your Standard Data Processing Addendum (approved Q3-2025) in 2 positions: (1) data residency location on line 12, (2) audit rights on line 27. Similar conflict was negotiated in [Vendor B contract, Aug-2025]-amendment template available." The answer cites the exact internal documents, reducing legal review time by 45-60 minutes per contract and eliminating hallucinated legal advice.
Impact: Law firms using Phoebe report 3.2x faster contract analysis and zero compliance violations from AI-assisted reviews-compared to 18% error rate with public LLM analysis.
Scenario 2: Edtech Personalized Learning Path Optimization
With Public LLM: An edtech curriculum coordinator asks ChatGPT: "Which students are likely to fail the final exam based on their Q1 performance data?" ChatGPT provides generic dropout risk factors (engagement metrics, prior GPA). But it has no access to your platform's learning data, student intervention history, or which teaching strategies actually improved outcomes for similar learners.
With Private AI (Phoebe): Phoebe searches student performance data, prior intervention records, and learning outcome analytics-all within your edtech platform. It returns: "Students with Q1 math scores <65% have 73% failure risk on final exam. Historical data shows 61% passed after Intervention Type C (peer tutoring + adaptive modules). [Student A] profile matches these patterns; recommend Intervention C starting Week 4. [Data from 2,847 students, 2024-2026]."
Why This Matters: Education datasets contain sensitive personal data about minors. Sending this to ChatGPT violates FERPA (Family Educational Rights and Privacy Act) and puts institutions at compliance risk. A single FERPA violation costs $43,280 in fines per student record. Phoebe keeps all student data within your platform.
Impact: Edtech platforms using Phoebe achieve 8-12% improvement in student retention and remain 100% FERPA-compliant.
Scenario 3: Sales Opportunity Qualification & Win-Loss Analysis
With Public LLM: A sales manager asks ChatGPT: "Should we discount 40% for this prospect, and how do we position against CompetitorX?" ChatGPT generates generic competitive positioning advice. It doesn't know that your last 7 discount negotiations in this prospect's industry averaged 18% margins, or that CompetitorX's strongest pitch is actually on feature Y (which your product uniquely handles). The sales team guesses, discounts heavily, and walks away with a 21% lowest-margin deal of the quarter.
With Private AI (Phoebe): Phoebe searches your CRM for similar deals, closed won/lost analysis, and customer deployment data. It returns: "Similar 5 deals in this industry averaged 31% margins at 15% average discount. CompetitorX won 3 of our 8 head-to-head competitions-all based on superior [Feature Y] throughput benchmarks (we lose by avg. 2.1x). Our [Feature Z] advantage is never mentioned but present in 4 of 5 won deals. Recommended positioning: lead with [Feature Z] ROI + benchmark [Feature Y] gains. Margin floor: 26%."
Impact: Sales teams using Phoebe increase deal margins by 18-23% and improve win rates against specific competitors by 31%-because recommendations cite actual historical data, not generic playbooks.
Data Point: [Forrester Study, 2025] Sales teams with AI-guided deal qualification close 4.2 days faster than those without.
Scenario 4: Customer Support Ticket Resolution & Knowledge Management
With Public LLM: A support agent encounters a customer asking: "Our API integration keeps dropping after 12 hours. How do I fix this?" They paste the customer message into ChatGPT. ChatGPT generates plausible-sounding troubleshooting steps based on generic API best practices-but doesn't know that your product has a known 12-hour session timeout bug (fixed in v4.2, reported in 3 of your last 47 tickets), or that 89% of customers experiencing this exact symptom have an incompatible middleware version. The agent gives the customer wrong guidance. The customer spends 6 hours troubleshooting. Satisfaction drops. Review: 2 stars instead of 5.
With Private AI (Phoebe): Phoebe searches your support ticket history, internal release notes, and customer environment data simultaneously. It returns:
"API drop after ~12 hours matches 3 prior tickets. Root cause: [12-hour session timeout bug in v3.x-v4.1]. Resolution: Upgrade to v4.2+ (released March-2026). Workaround (immediate): Set session refresh interval to 8 hours in config. Customer currently running v3.8-recommend upgrade path with migration guide [link]. ETA to resolution: 15 minutes vs. 6+ hours of generic troubleshooting."
Why This Matters: 67% of support costs come from handling repeated issues. Phoebe eliminates most repeat tickets by retrieving exact solutions from your internal knowledge base-not AI hallucinations.
Impact: Customer support teams using Phoebe reduce average resolution time by 56%, improve first-contact resolution rate from 38% to 74%, and increase CSAT scores by 0.8 points on average (out of 5).
Compliance Win: All customer data stays in your support system-no data sent to third-party APIs. Maintains SOC 2, GDPR, and PCI-DSS compliance without extra overhead.
The Compliance Imperative: Regulations Are Catching Up
Global AI Governance Tightening in 2025–2026 Across All Industries
- EU AI Act (2025): High-risk AI systems used across financial, legal, healthcare, and education sectors now require extensive documentation, human oversight, and data governance-incompatible with ad-hoc public LLM use
- India DPDP Act (2023, enforcement 2025): All organizations processing personal data through AI must have explicit consent mechanisms and data minimization policies. Non-compliance fine: ₹500 crore or 2% of worldwide revenue.
- US Executive Order on AI (2023): Federal agencies and contractors required to implement AI safety standards-effectively prohibiting uncontrolled public LLM use for regulated work
- FERPA (US Education): Educational institutions sending student data to public LLMs face $43,280+ per-record fines and loss of federal funding eligibility
- SEBI/RBI (India Finance): Regulated financial entities explicitly warned against using external AI APIs for compliance, KYC, or client-data workflows
- GDPR Article 46 (EU): International data transfers without Standard Contractual Clauses now face heightened scrutiny; public LLM use increasingly fails compliance audits
The regulatory trajectory is unambiguous: organizations that deploy private AI infrastructure now will be positioned for compliance; those relying on public LLMs face exponential retrofit costs and regulatory penalty exposure.
A single data protection violation can trigger massive fines:
- GDPR violation: €20 million or 4% of global annual turnover (whichever is higher)
- India DPDP violation: ₹500 crore or 2% of worldwide revenue
- FERPA violation (per student record disclosed): $43,280
- HIPAA violation (per patient): Up to $1.5 million across violation categories
For most enterprises, deploying a private AI infrastructure costs 2-8% of these potential fines-making it the cost-effective choice beyond just compliance.
How Phoebe by AstraQ Enables Private Enterprise AI Across Industries
Private, enterprise-grade AI needs to be more than just secure-it needs to be accurate, current, and embedded in the workflows where decisions happen. This is exactly what Phoebe, AstraQ's private Retrieval-Augmented Generation (RAG) system, delivers across legal, edtech, sales, and support organizations.
Phoebe is AstraQ's enterprise RAG system built for high factual accuracy and full traceability across sensitive enterprise data. It combines semantic chunking, hybrid retrieval (dense, sparse, and late interaction), and citation-aware generation to deliver reliable, hallucination-minimized answers from your own complex document corpora-entirely within your infrastructure, ensuring data never leaves your perimeter.
Why Phoebe Is Built for Enterprise Workloads Across Industries
| Enterprise Requirement | How Phoebe Addresses It | Impact |
|---|---|---|
| Data never leaves perimeter | Fully on-premise or private cloud deployment-no external API calls | 100% compliance with GDPR, DPDP, FERPA, PCI-DSS |
| Accurate domain-specific answers | Hybrid retrieval grounds every answer in your actual internal knowledge base | 45-60% faster legal reviews; 8-12% higher student retention |
| No hallucinated intelligence | Citation-aware generation links every claim to specific source documents | Zero unsubstantiated legal advice; 31% better sales win rates |
| Auditability & compliance | Full query and retrieval logging for regulatory review and forensics | Audit-ready evidence trails for compliance assessments |
| Real-time knowledge freshness | Dynamic ingestion of contracts, student data, CRM records, tickets, policies | Answers reflect current state-no stale data |
| Domain adaptability | Indexes your legal docs, curriculum, CRM, support tickets, policies out of the box | Multi-industry deployment in weeks, not months |
What Organizations Across Industries Can Do With Phoebe
Legal & Compliance Teams:
- Contract compliance checking: "Does this vendor SLA meet our data residency requirements?"-answered with exact citations to your Standard Terms Addendum and prior negotiations
- Regulatory mapping: "Which of our contracts fall under India's DPDP Act Tier 1 jurisdiction?"-cross-referenced from your contract corpus and compliance framework
- Due diligence acceleration: Condense 500-page M&A legal reviews into executive summaries with tagged risk sections-all documents stay within your secure environment
Edtech Platforms & Educators:
- Student intervention targeting: "Which at-risk students should receive tutoring support based on Q1 performance?"-answered from historical intervention outcome data
- Curriculum optimization: "Which learning modules have the lowest completion rates for demographic group X?"-analyzed from aggregated student performance data (fully FERPA-compliant)
- Personalized learning paths: Match struggling students to intervention strategies that worked for similar learners in prior cohorts
Sales & Revenue Teams:
- Competitive intelligence: "How did we position against CompetitorX in past deals, and which angles won?"-retrieved from your CRM closed-won analysis
- Deal qualification: "What margin should we defend for this prospect's industry and company size?"-answered from deal history and win-loss data
- Sales playbook generation: Automatically surface the most relevant case studies and objection handling strategies based on prospect profile
Customer Support & Success:
- Ticket resolution acceleration: "We've seen this customer error before-what was the fix?"-retrieved from ticket history with exact solution steps
- Knowledge base synthesis: Automatically match incoming customer questions to relevant help articles, past ticket resolutions, and internal FAQs
- Proactive support: Identify customers experiencing repeated issues and auto-route escalations with full context on prior interactions
Common Organizations' Measurable Outcomes:
- Legal/Compliance: 45-60 min faster per contract review; 99.2% compliance accuracy vs. 81.4% with ChatGPT
- Edtech: 8-12% higher student retention; 100% FERPA compliance
- Sales: 18-23% higher deal margins; 31% better win rates against named competitors
- Support: 56% faster resolution; 74% first-contact resolution (vs. 38% baseline)
"Phoebe doesn't just answer questions-it shows you exactly which document it drew each conclusion from. In enterprise AI, that traceability isn't optional. It's the foundation of compliance and trust."
Explore Phoebe and request a private deployment consultation
Transitioning From Public LLMs to Private AI: A Practical Roadmap
Making the switch doesn't require abandoning AI productivity-it requires redirecting it to the right infrastructure. Industry-specific implementations vary, but the architecture pattern is consistent.
Phase 1–Audit and Classify (Weeks 1–2)
- Identify current usage: Map all public LLM usage across the organization (legal teams using ChatGPT for contracts, support staff uploading customer tickets, sales sharing deal data, educators analyzing student results)
- Classify sensitivity: Categorize data being sent by protection level (GDPR, FERPA, PCI-DSS, DPDP, etc.)
- Quantify risk: Calculate your regulatory fine exposure if data is breached or misused
Phase 2–Document Ingestion Infrastructure (Weeks 3–6)
- Identify knowledge sources: Gather contracts, curricula, CRM records, support tickets, policies, procedures
- Set up secure storage: Build an isolated vector database and metadata store in your perimeter
- Establish ETL pipelines: Create automated ingestion for contracts (legal), student data (edtech), sales records (revenue), and ticket submissions (support)
Phase 3–Private AI Deployment (Weeks 6–12)
- Deploy private RAG: Install Phoebe or equivalent on-premise or in your private VPC with hybrid retrieval
- Integrate with existing tools: Connect to your document management systems, CRM, LMS, ticketing platforms
- Establish security: Set role-based access control, audit logging, and query monitoring
Phase 4–User Enablement and Policy (Ongoing)
- Train teams on the capabilities and limitations of private AI within their workflow
- Formalize policy: Document the "no sensitive data to public LLMs" rule with enforcement mechanisms
- Measure impact: Track improvement metrics-contract review time, student outcomes, deal margins, ticket resolution time
For teams already thinking about RAG evaluation methodology, our Evaluating RAG Systems with RAGAS post covers the key metrics-faithfulness, answer relevancy, context precision, and context recall-that determine whether your private AI system is actually working as intended.
And if you're building the retrieval layer from scratch, our Production-Ready RAG Guide walks through the full technical architecture for enterprise-grade retrieval pipelines.
Conclusion: The Security of AI Depends on Where It Lives
The question for enterprise leaders is no longer whether to use AI-it's where that AI lives and whose data it learns from.
Public LLMs were designed for consumer convenience and breadth. They were never designed for:
- Legal precision: Accurate contract analysis grounded in your actual terms and precedents
- Educational compliance: FERPA-compliant student data analysis without external exposure
- Sales intelligence: Deal strategies based on your actual closed-won history, not generic advice
- Customer empathy: Support resolution grounded in your specific customer context
The Samsung incident in April 2023 was a warning. The EU AI Act enforcement in 2025 is a deadline. The regulatory fines-€20M+ for GDPR, ₹500Cr for DPDP, $43,280 per FERPA violation-are immediate consequences.
Organizations deploying private AI infrastructure today will be positioned for compliance, accuracy, and competitive advantage. Those relying on public LLMs for business-critical workflows face exponential retrofit costs, regulatory penalties, and the reputational damage of data breaches.
Private AI-grounded in your own data, contained within your perimeter, and auditable at every step-is not the cautious choice. Given the regulatory and operational landscape of 2026, it's the only defensible one.